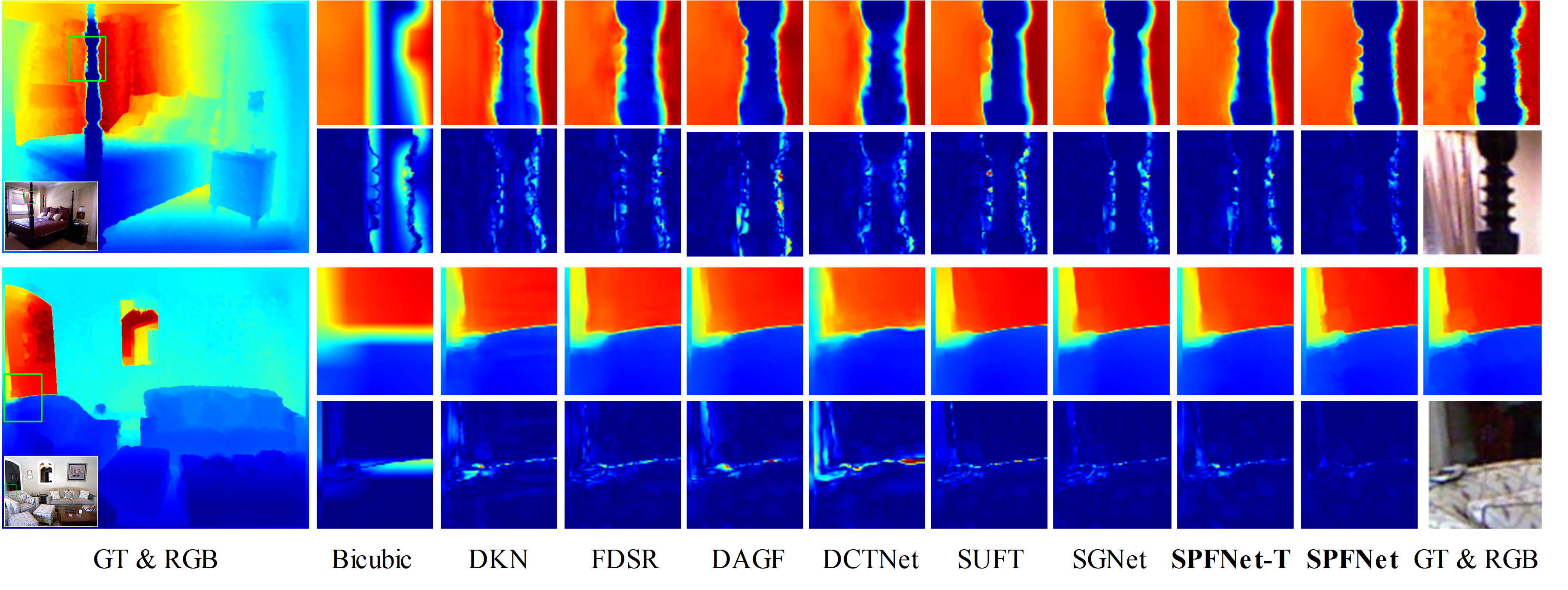
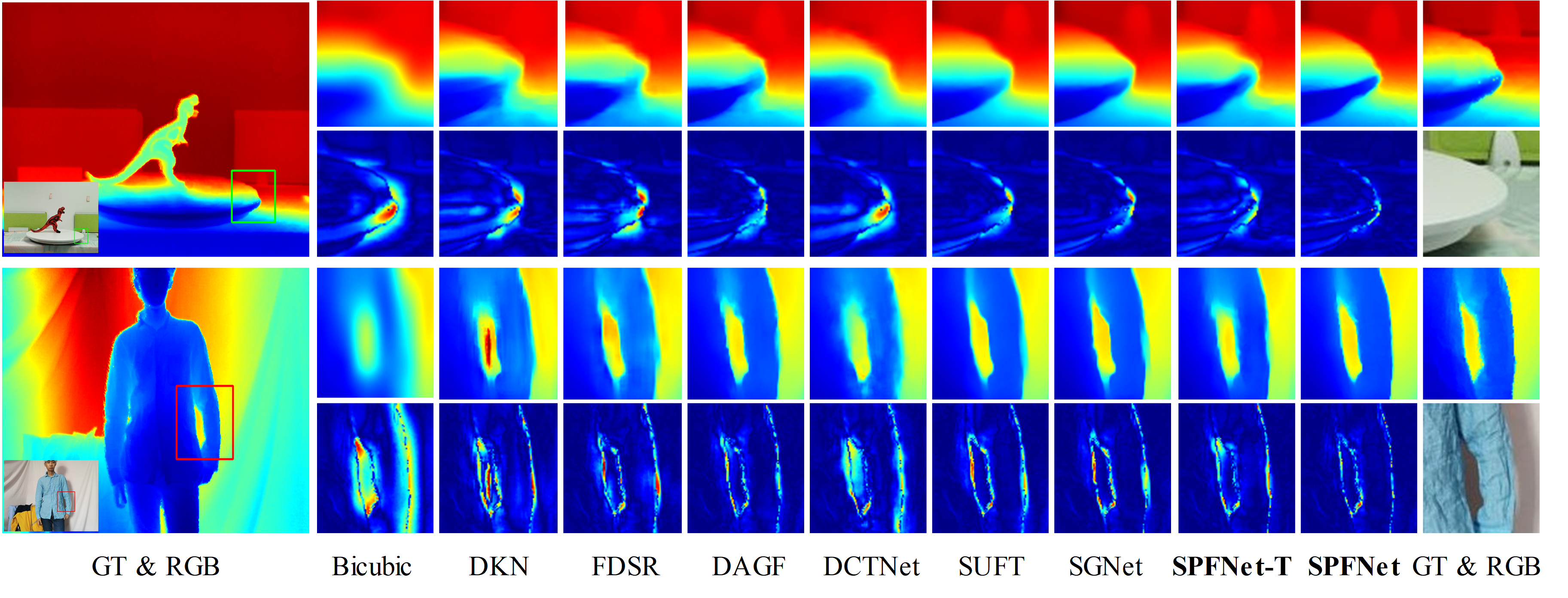
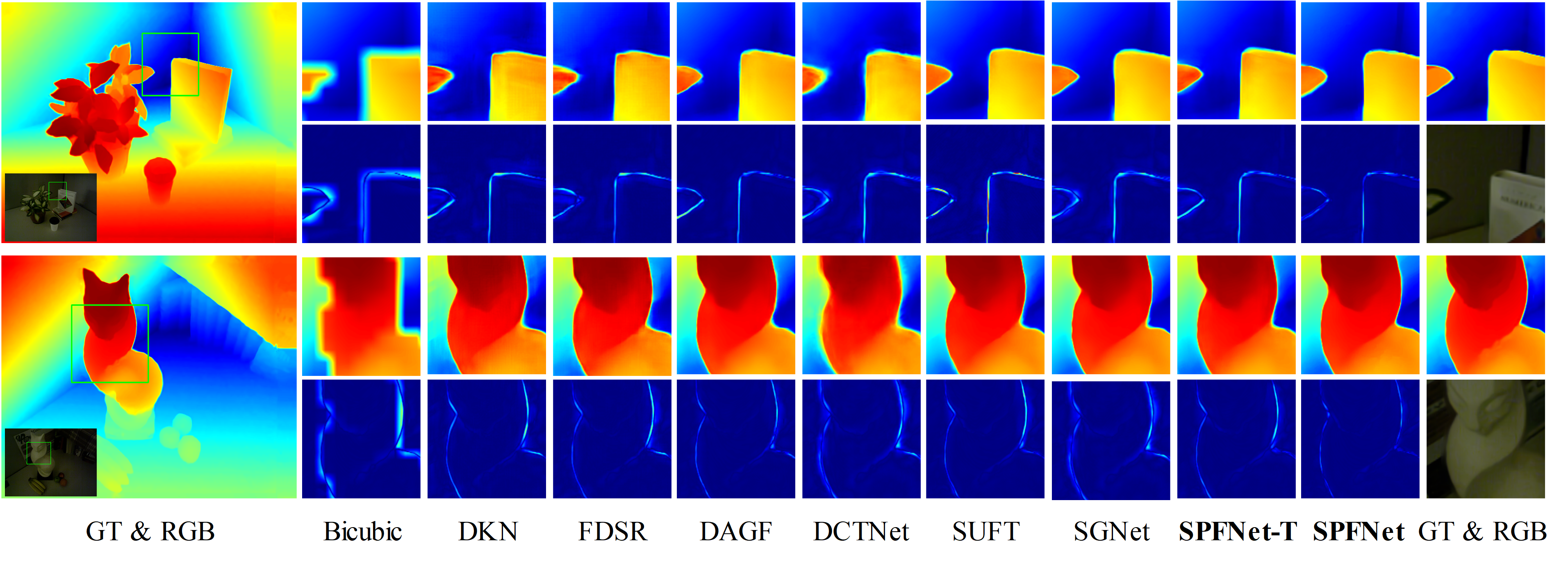
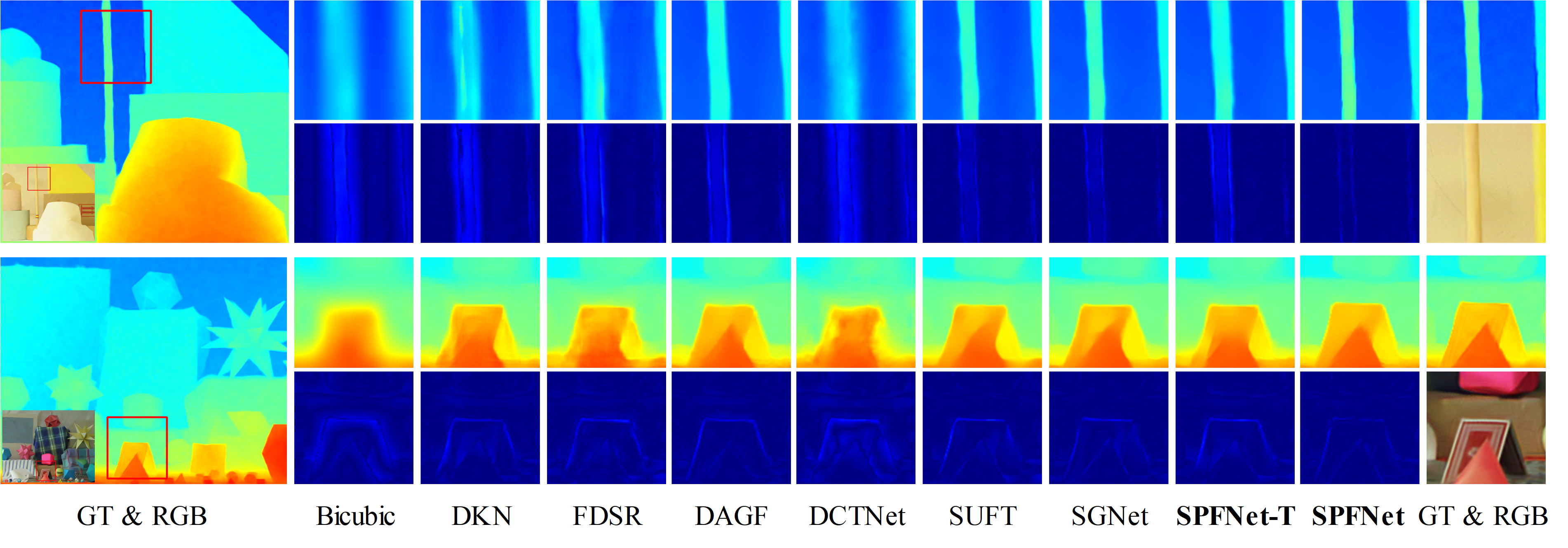
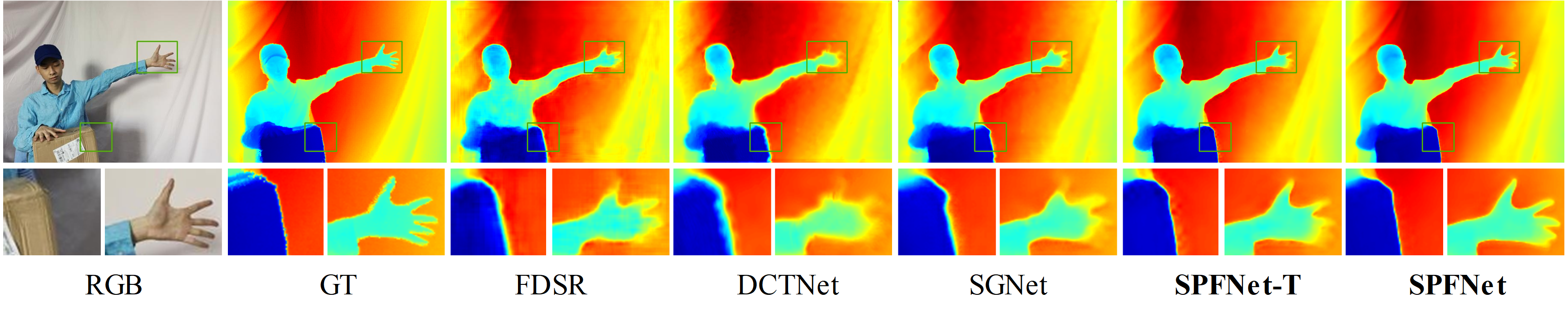
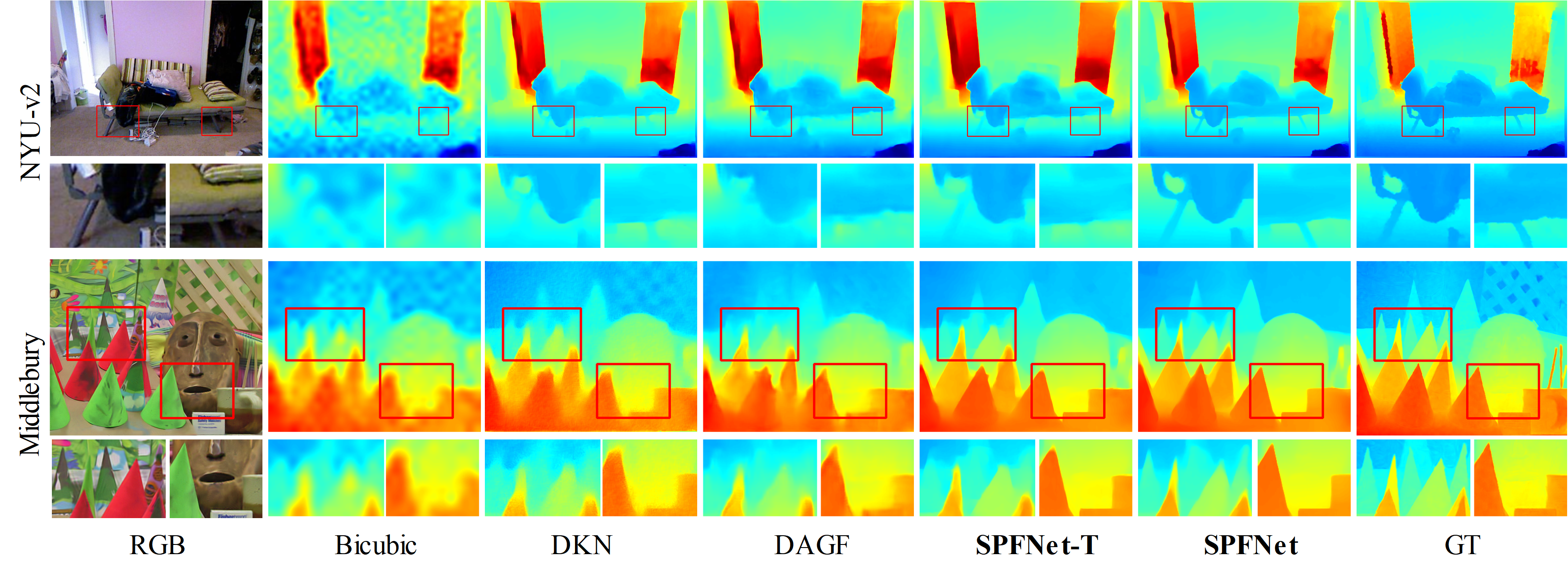
Abstract
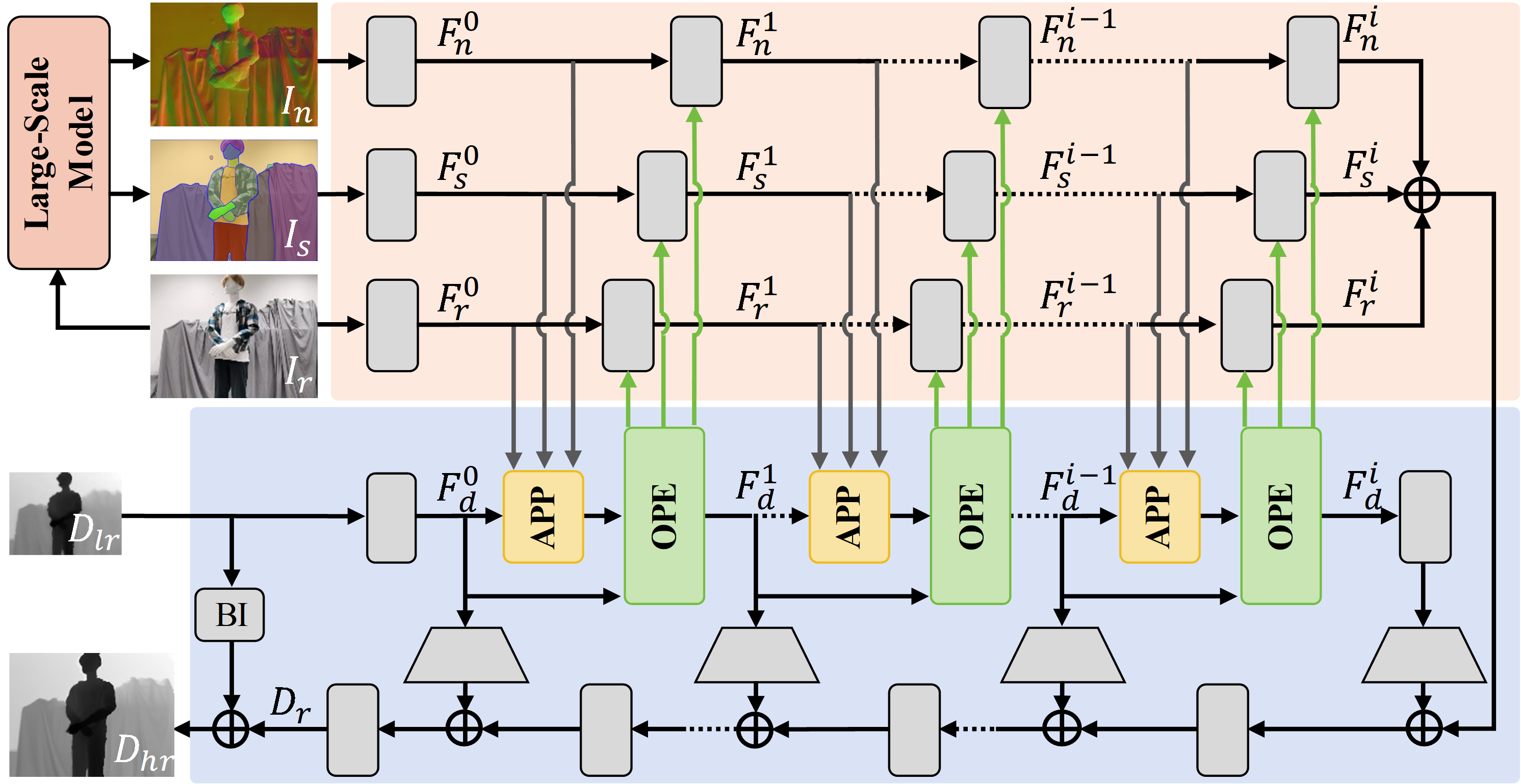
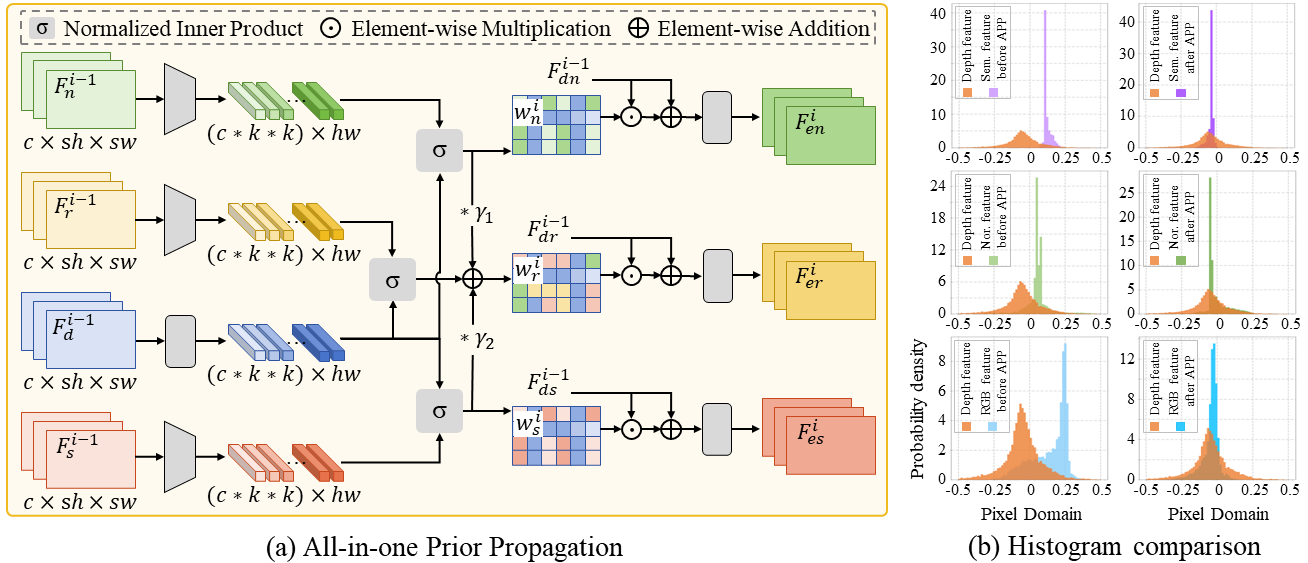
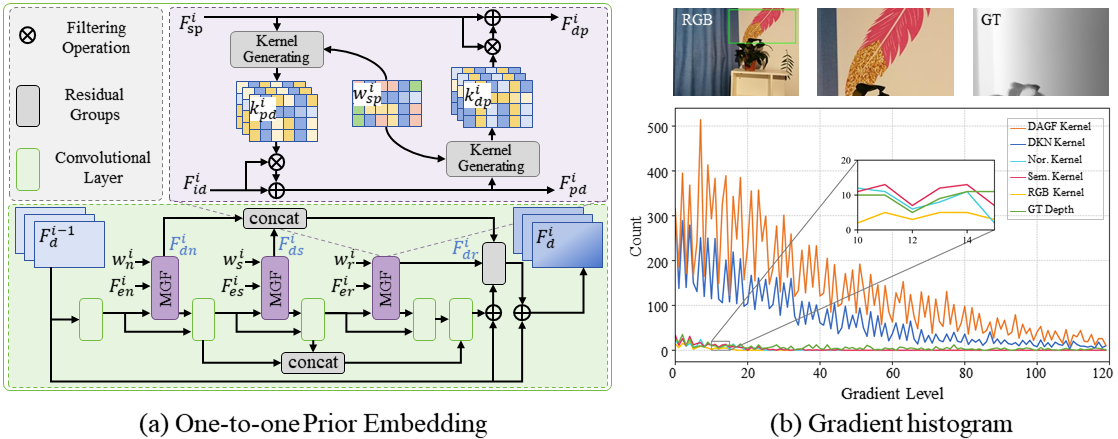
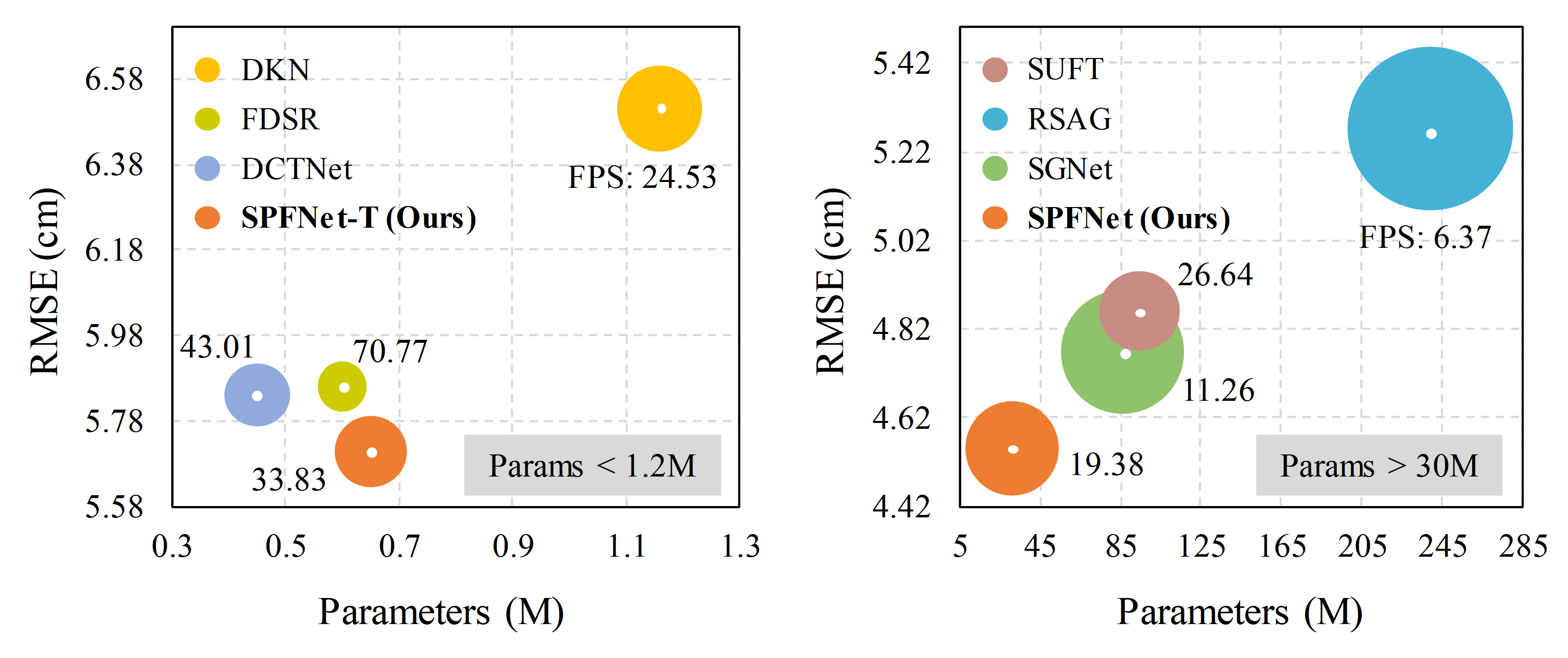
Multi-modal fusion is vital to the success of super-resolution of depth images. However, commonly used fusion strategies, such as addition and concatenation, fall short of effectively bridging the modal gap. As a result, guided image filtering methods have been introduced to mitigate this issue. Nevertheless, it is observed that their filter kernels usually encounter significant texture interference and edge inaccuracy. To tackle these two challenges, we introduce a Scene Prior Filtering network, SPFNet, which utilizes the priors surface normal and semantic map from large scale models. Specifically, we design an All-in-one Prior Propagation that computes the similarity between multi-modal scene priors, i.e., RGB, normal, semantic, and depth, to reduce the texture interference. In addition, we present a One-to-one Prior Embedding that continuously embeds each single-modal prior into depth using Mutual Guided Filtering, further alleviating the texture interference while enhancing edges. Our SPFNet has been extensively evaluated on both real and synthetic datasets, achieving state-of-the-art performance. The source codes and pre-trained models are available at https://github.com/yanzq95/SPFNet.